|
I’m a Master’s student in Computer Vision (MSCV) at Carnegie Mellon University (Class of 2026), part of the School of Computer Science. My work focuses on deep learning for computer vision, generative modeling, and large-scale visual representation learning. I am currently a Research Assistant at the CMU Tepper School of Business (predicting engagement patterns in short-form video), and a member of Team CHIRON at Airlab, CMU under Prof. John Galeotti, contributing to the DARPA TRIAGE Challenge. My work focuses on data engineering and Vision-Language Models (VLMs) for real-world triage intelligence systems. I was previously part of the Xu Lab at CMU, where I worked on DUAL — an unsupervised cryo-ET denoising and synthetic data generation framework. During my undergrad, I worked as a Research Intern at the University of Mumbai where I developed ColourViTGAN and a dual-attention few-shot learning model — both first-author IEEE publications that received Best Paper Awards. I also interned at IIT Bombay and Wondrlab India Pvt. Ltd.. I will be joining Microsoft as an Applied Sciences Intern (Summer 2026). I hold a Bachelor’s in Computer Engineering from Thadomal Shahani Engineering College, affiliated with Mumbai University. Actively Seeking Full-Time ML/CV Research & Engineering Roles (2026). |

|
|
|
|
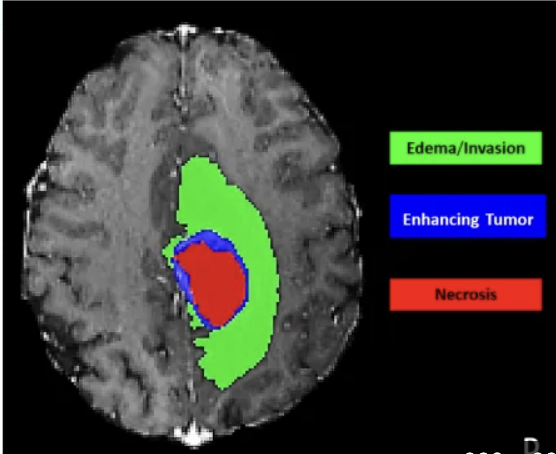
Designed a novel medical image segmentation framework that adapts pretrained Vision-Language Models (VLMs) to MRI data using Low-Rank Adaptation (LoRA), achieving domain transfer without full re-training. Integrated a dual-branch global–local architecture where global features capture anatomical structure while local features specialize in tumor sub-regions (edema, non-enhancing, enhancing core). Implemented a lightweight cross-attention fusion module and evaluated on the BraTS dataset to demonstrate improved tumor boundary detection, reduced trainable parameters, and lower memory footprint compared to full fine-tuning and U-Net baselines. |

|
Developed a multimodal cardiac risk assistant powered by Random Forest risk prediction, ECG deep learning, and a fine-tuned medical LLM. Built a PubMedBERT-based Q&A model trained on MEDQA and PubMed corpora for clinically accurate recommendations, and a CNN-LSTM pipeline for ECG arrhythmia classification on the PTB-XL dataset. Achieved 76.8% EM accuracy on medical responses and 0.875 AUC for ECG classification. |
|
|
|
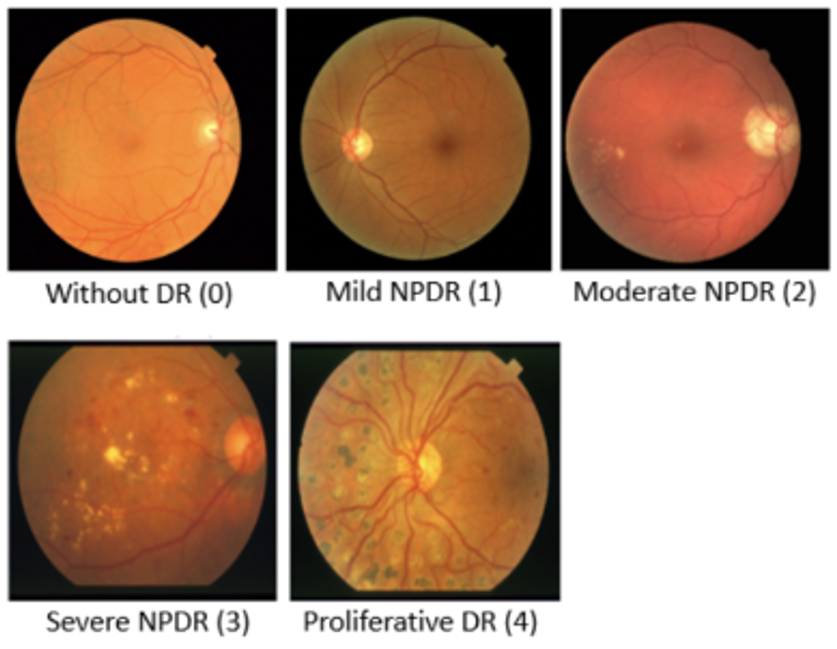
[pdf] [best paper] Early detection of microaneurysms in diabetic retinopathy (DR) is critical for preventing vision loss but remains challenging due to limited labeled data and subtle lesion features. This study introduces a few-shot learning model integrating dual attention mechanisms with prototypical networks to address these challenges. Enhanced with spatial and channel attention modules, our modified ResNet-50 backbone achieves precise localization and adaptive feature weighting. First-author IEEE publication, awarded Best Paper (Rank 1). |

|
[pdf] [best paper] ColourViTGAN is a novel hybrid approach combining Vision Transformers (ViTs) and CycleGANs to achieve superior image recolorization for grayscale inputs. By integrating ViTs into both the generator and discriminator, the model captures long-range dependencies while preserving local details. Custom perceptual loss functions and advanced regularization techniques further enhance stability and performance. ColourViTGAN surpasses state-of-the-art models like Pix2Pix and ChromaGAN in terms of PSNR, SSIM, and LPIPS. First-author IEEE publication, awarded Best Paper (Rank 1). |
|
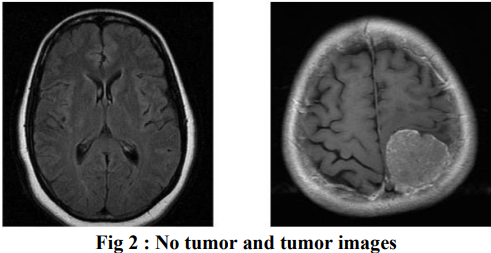
Early and accurate diagnosis of brain tumors is critical for effective treatment and improved survival rates. While MRI scans are invaluable non-invasive tools, their manual interpretation is labor-intensive due to the complexity of 3D imaging. This study leverages cutting-edge deep learning models-CNN, VGG16, VGG19, ResNet-50, MobileNet, and InceptionV3-to automate brain tumor detection, achieving remarkable accuracy scores: CNN (97.55%), VGG16 (97.96%), and InceptionV3 (97.55%) patient outcomes. |
|
This study addresses the challenges of color vision deficiencies, particularly tritanopia, by proposing an innovative image transformation approach to enhance color perception. Using convolutional autoencoders, our method converts blue hues into indigo shades, making them more distinguishable for individuals with tritanopia. Training on a specialized dataset derived from COCO2017, we optimize for accuracy, precision, and perceptual fidelity using TensorFlow and Keras. |
|
[Feb 2026] Paper ModelFabric submitted to ICML'26 [Jan 2026] Joined Team Chiron at the Airlab CMU for participating in the DARPA Triage Challenge. [Nov 2025] Joined CMU Tepper School of Business as Research Assistant [Oct 2025] Started as Research Assistant at Xu Lab, CMU [Sep 2025] Accepted into Carnegie Mellon University - Master’s in Computer Vision (MSCV) [Jul 2025] Graduated with B.E. in Computer Engineering from Thadomal Shahani Engineering College, affiliated with University of Mumbai [Mar 2025] Completed Research Internship at M. H. Saboo Siddik College of Engineering, affiliated with University of Mumbai [Aug 2024] Concluded Summer Internship at IIT Bombay [Sep 2023] Completed SWE Internship at Wondrlab India Pvt. Ltd. |
|
Source code from Jon Barron |